The first 30 minutes decide whether you catch the deadlock
A stuck I/O incident looked invisible in logs, metrics, and traces. The useful evidence came from reproducing the hang, forcing a core dump, and proving the mutex owner cycle in gdb.
The service is alive. CPU is low. Error rate is climbing. A few requests are timing out.
Dashboards say "stuck I/O".
Traces end in waiting spans. The logs say almost nothing, because nothing is crashing. There are no errors to grep.
Logs, metrics, and traces can narrow the blast radius.
They usually cannot prove this class of runtime bug.
That is exactly why the first 30 minutes of an investigation matter.
If the process is still wedged, the whole truth is still in memory.
the symptom lied
The incident looked like stuck I/O.
Requests entered the service and then sat there. The trace spans made the storage layer look suspicious.
The obvious move was to go read logs, traces, and look for errors. Not much luck there.
They were useful for validating one fact:
The service is not making progress.
They could not answer the question that mattered: why.
To answer this question, you have to enter the live environment and experiment.
freeze the evidence
If you can get to the affected machine in the minutes after the bug appears, you still have the evidence most teams accidentally delete.
Experienced engineers already know this.
Take the affected replica out of traffic. Keep the host warm.
Then capture the process state.
# less destructive snapshot, if gcore is available
sudo gcore -o /var/tmp/myservice.core "$(pidof myservice)"
# or, when the replica is already wedged and safe to crash,
# abort intentionally so the runtime writes a core dump
sudo kill -ABRT "$(pidof myservice)"
Open the binary and the dump:
gdb /opt/myservice/bin/myservice /var/tmp/myservice.core.31415
At this point, you are no longer asking the observability stack what happened.
You are interrogating the process that failed.
the stack is not proof
The first gdb pass was suggestive.
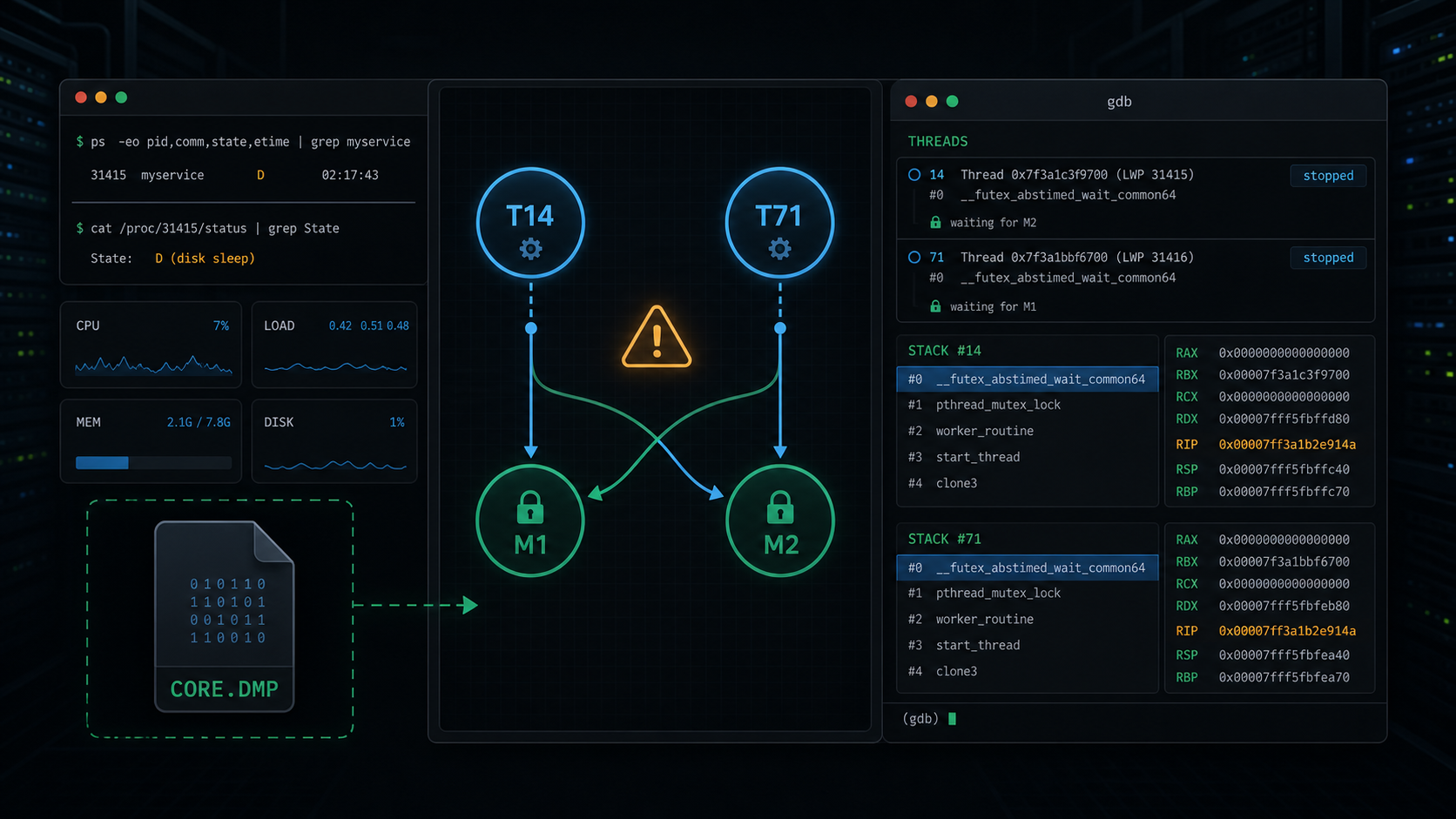
(gdb) info threads
14 Thread 0x7f3a1c3f9700 (LWP 31471) __futex_abstimed_wait_common64
71 Thread 0x7f3a1bbf6700 (LWP 31528) __futex_abstimed_wait_common64
Thread 14 looked like this:
main()
process_data()
std::mutex::lock()
__pthread_mutex_lock_full()
__futex_abstimed_wait_common64()
BLOCKED
Hmm waiting on a mutex.
A deadlock, perhaps?
You spend some more time looking around to see what was happening in the system.
And then you spot something else.
Thread 71 was also stuck in mutex wait:
main()
clear_cache()
std::mutex::lock()
__pthread_mutex_lock_full()
__futex_abstimed_wait_common64()
BLOCKED
That still does not prove a deadlock.
You lookup the code for process_data() and clear_cache().
std::mutex metadata_mu;
std::mutex cache_mu;
void process_data() {
// Wall of code
std::lock_guard<std::mutex> a(metadata_mu);
// Wall of code
write_metadata();
// Wall of code
std::lock_guard<std::mutex> b(cache_mu);
update_cache_index();
}
void clear_cache() {
// Wall of code
std::lock_guard<std::mutex> b(cache_mu);
// Wall of code
std::lock_guard<std::mutex> a(metadata_mu);
rewrite_metadata();
}

ask the lock
The real move is to inspect the mutex object itself.
First, switch to Thread 14 and find the mutex it is trying to acquire.
(gdb) thread 14
[Switching to thread 14 (LWP 31471)]
(gdb) bt
#0 __futex_abstimed_wait_common64
#1 __pthread_mutex_lock_full
#2 std::mutex::lock()
#3 process_data()
#4 main()
(gdb) frame 1
#1 __pthread_mutex_lock_full (mutex=0x00007f4c2a40b8d0)
(gdb) p mutex
$1 = (pthread_mutex_t *) 0x00007f4c2a40b8d0
Then look at the mutex internals.
On glibc, pthread_mutex_t carries an owner field. It stores the owner LWP, not the pretty gdb thread number, so you match it back against info threads.
(gdb) p ((pthread_mutex_t *)0x00007f4c2a40b8d0)->__data.__owner
$2 = 31528
31528 is Thread 71's LWP.
So Thread 14 is blocked on a mutex owned by Thread 71.
Now do the same thing from Thread 71.
(gdb) thread 71
[Switching to thread 71 (LWP 31528)]
(gdb) bt
#0 __futex_abstimed_wait_common64
#1 __pthread_mutex_lock_full
#2 std::mutex::lock()
#3 clear_cache()
#4 main()
(gdb) frame 1
#1 __pthread_mutex_lock_full (mutex=0x00007f4c2a417920)
(gdb) p mutex
$3 = (pthread_mutex_t *) 0x00007f4c2a417920
(gdb) p ((pthread_mutex_t *)0x00007f4c2a417920)->__data.__owner
$4 = 31471
31471 is Thread 14's LWP.
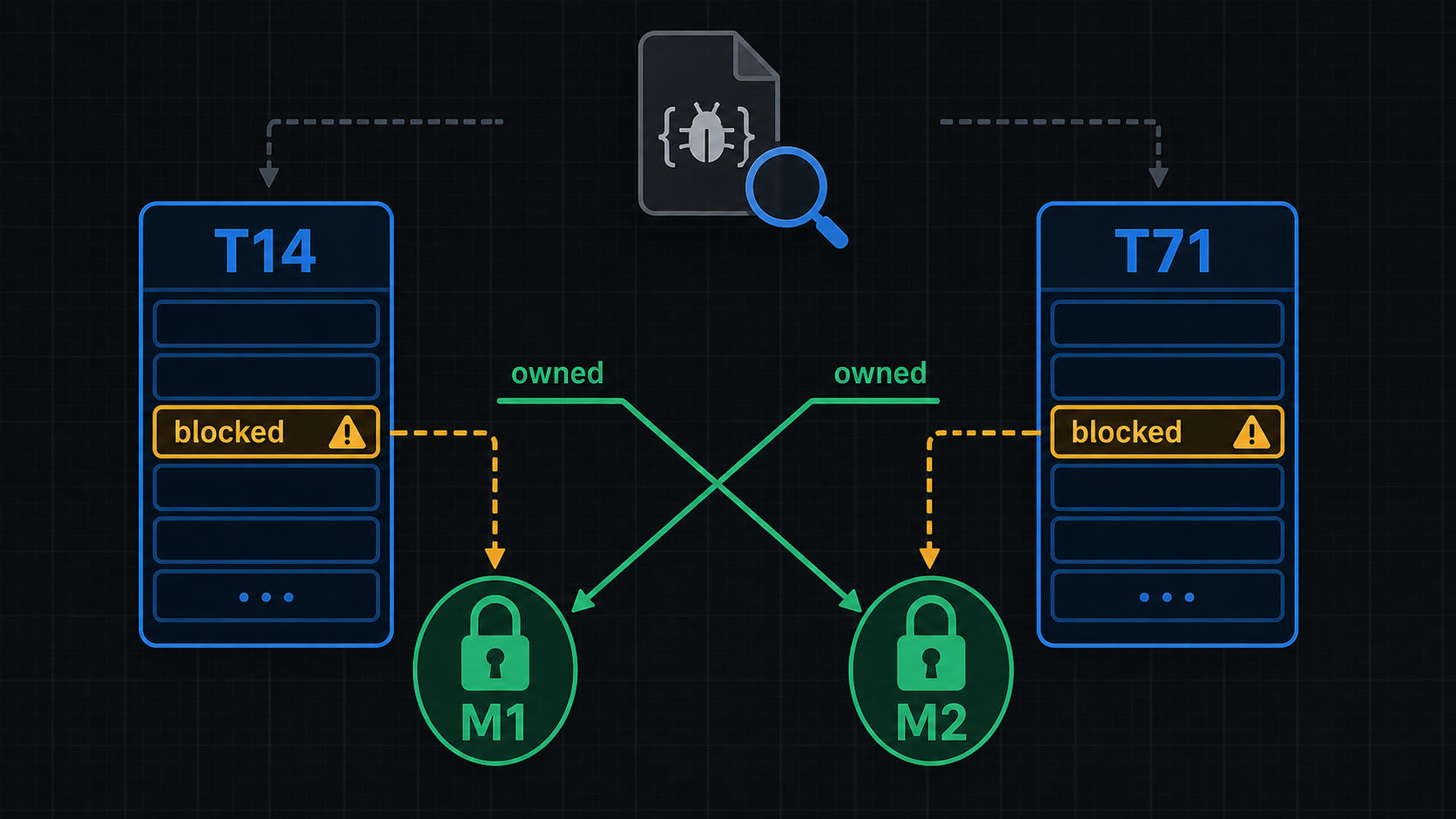
That is the bug.
Not a vibe. Not "probably a deadlock." Not "the storage layer is acting weird."
Thread 14 waits on M1. M1 is owned by Thread 71.
Thread 71 waits on M2. M2 is owned by Thread 14.
what the first 30 minutes are for
The first 30 minutes are not for collecting everything.
They are for preserving the evidence that will disappear.
For this class of incident, the useful workflow is short:
1. Keep the affected process alive.
2. Remove it from traffic if needed.
3. Capture a core dump.
4. Inspect blocked threads in gdb.
5. Trace the lock ownership cycle.
6. Ask your boss for a raise.
If you stare at the data dump produced by observability for an hour, the host may be replaced, the process may be gone, and you missed the chance to fix the bug.
By then you are no longer debugging the system that failed.
You are debugging whatever evidence survived.
The bug was not "I/O is slow."
The bug was a lock cycle wearing an I/O costume.
where agents should help
This is the bar AI SRE tooling needs to clear.
Not just "summarize the incident after the fact."
That is useful, but late.
The useful agent arrives while the process is still warm. It notices the stuck-I/O shape, preserves the live state, asks for permission before destructive steps, captures the core, ranks the deadlock hypothesis, and leaves a small evidence ledger:
Hypothesis: lock inversion between process_data() and clear_cache()
Evidence:
- Thread 14 blocked in pthread_mutex_lock
- Thread 71 blocked in pthread_mutex_lock
- M1 owner LWP = 31528 -> gdb thread 71
- M2 owner LWP = 31471 -> gdb thread 14
Next test:
- enforce lock ordering or replace nested locks, then reproduce under stress
That is the shape we are building toward with FixBugs: not a prettier incident summary, but a debugging agent that preserves volatile evidence, experiments, hypothesizes and interacts with the application to reproduce the bug.
For the broader AI SRE workflow, this distinction matters.
The worst bugs do not always shout in logs. Sometimes they sit quietly in memory, beyond the reach of observability.